
八、k8s持久化存储
本节k8s集群环境如下
| 角色 | IP | 主机名 | 组件 | 硬件 |
|---|---|---|---|---|
| 控制节点 | 192.168.128.11 | k8s-master-01 | apiserver controller-manager scheduler etcd containerd | CPU:4vCPU 硬盘:50G 内存:4GB 开启虚拟化 |
| 工作节点 | 192.168.128.21 | k8s-node-01 | kubelet kube-proxy containerd calico coredns | CPU:2vCPU 硬盘:25G 内存:2GB 开启虚拟化 |
| 工作节点 | 192.168.128.22 | k8s-node-02 | kubelet kube-proxy containerd calico coredns | CPU:2vCPU 硬盘:25G 内存:2GB 开启虚拟化 |
1.为什么要做持久化存储
在k8s中部署的应用都是以pod容器的形式运行的,假如我们部署MySQL、 Redis 等数据库,需要对这些数据库产生的数据做备份。因为Pod是有生命周期 的,如果pod不挂载数据卷,那pod被删除或重启后这些数据会随之消失,如果 想要长久的保留这些数据就要用到pod数据持久化存储。
查看k8s支持哪些存储、可以使用下面命令进行查询
kubectl explain pods.spec.volumes
k8s支持多种不同类型的存储:
1、空白存储(EmptyDir):一个临时目录,只在Pod的生命周期中存在。
2、主机路径(HostPath):在宿主机上创建并挂载一个目录,作为Pod中的存储卷。(生产环境慎用)
3、基于网络的存储(Network-basedstorage):使用网络存储,如NFS(原生插件被弃用、需通过csi驱动实现)、 iSCSI等。
4、持久化卷(PersistentVolume):由管理员分配并预设置的存储卷。它们可以在多个Pod和节点之间动态地共享和重新分配。
5、存储类(StorageClass):对于动态分配的持久化卷,允许管理员创建不同的存储类,以满足应用程序不同的存储要求。存储类会根据现有的存储池来创建新的存储。
6、对象存储(ObjectStorage):例如AmazonS3,使用外部存储来存储数据。
7、本地存储(Local Storage):使用主机的本地存储,适合于需要高效 I/O的应用程序。
总之,Kubernetes支持多种存储类型,根据不同的应用场景进行选择和配置
2.k8s持久化存储EmptyDir
EmptyDir是一种k8s中的持久化存储卷、它可以在pod的生命周期内持久保存数据、当容器使用EmptyDir卷时、k8s会在节点上为其分配一个空目录、在pod的生命周期内、这个目录将会一直存在、可以在容器之间共享、如果容器重启或迁移、数据也将保持不变
EmptyDir的数据仅在单个节点上持久、如果该节点发生故障或pod迁移到其他节点、数据将丢失
实战:创建一个pod挂载临时目录、测试清除pod、临时目录的数据是否会丢失
//创建资源清单文件、使用emptyDir挂载临时目录
vi emptydir.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-empty
spec:
containers:
- name: container-empty # 容器名称
image: nginx # 使用 nginx 镜像
volumeMounts:
- mountPath: /cache # 将卷挂载到容器内的 /cache 目录
name: cache-volume # 引用的卷名称
volumes:
- name: cache-volume # 定义卷名称
emptyDir: {} # 使用 emptyDir 临时存储卷
这个配置声明了一个名为pod-empty的Pod,在Pod中有一个名为container-empty的
容器,容器会挂载一个名为cache-volume的EmptyDir卷,并将其挂载到容器的/cache目
录下。
spec.volumes中的emptyDir对象声明了一个空的EmptyDir存储卷。此时,Kubernetes
将在当前节点上为此Pod创建一个新的临时目录,并将其与该卷绑定。
spec.containers.volumeMounts中声明了如何将此EmptyDir挂载到容器中。在这个示
例中,容器的/cache目录将映射到该卷上,因此容器中的应用程序可以在此目录中创建和
访问文件。
需要注意的是,EmptyDir存储卷的生命周期与Pod的生命周期相同,如果Pod被删除
或终止,则其中包含的所有数据也将被删除。因此,EmptyDir更适合于临时存储或缓存,而不是长期数据持久化。
//更新资源清单文件
kubectl apply -f emptydir.yaml
//查看pod、查看pod=empty调度到了哪个节点
kubectl get pods -o wide
//查找Pod的UID和卷路径
# 方法1:直接获取Pod UID
kubectl get pod pod-empty -o jsonpath='{.metadata.uid}'
# 方法2:通过describe命令找到Volume路径(更可靠)
kubectl describe pod pod-empty | grep -A5 "Volumes:"
# 输出示例会显示实际路径:/var/lib/kubelet/pods/<uid>/volumes/kubernetes.io~empty-dir/cache-volume
//在对应节点查看、字段--volumes就是
tree /var/lib/kubelet/pods/9a9ef367-9a7b-47b0-bc24-bfcfc39890d8/
//测试
//在临时目录下创建文件
cd /var/lib/kubelet/pods/9a9ef367-9a7b-47b0-bc24-bfcfc39890d8/volumes/kubernetes.io~empty-dir/cache-volume
echo "I am xxx" > name.txt
ls
cat name.txt
//进入pod-empty容器内查看文件是否存在
kubectl exec -it pod-empty -- /bin/bash
cat /cache/name.txt # 应看到"I am xxx"
//删除pod后验证数据是否清除
kubectl delete -f emptydir.yaml
//再次检查节点目录(目录应已被自动删除)
ls /var/lib/kubelet/pods/9a9ef367-9a7b-47b0-bc24-bfcfc39890d8 # 无此目录
3.k8s持久化存储hostPath
hostPath是Kubernetes中一种简单的持久性存储卷类型,它可将节点的文 件系统中的文件或目录直接挂载到Pod中。
该卷类型通过在Pod中指定主机路径和容器中所需挂载该路径的位置来工 作。它适用于需要访问节点中文件系统上的目录或文件的应用程序。
需要注意的是,使用hostPath存储卷需要非常小心,因为它会直接暴露节 点的文件系统。另外,当Pod迁移到其他节点时,这个目录映射不会跟随迁移而 改变,因此可能会影响到应用程序的可移植性。
hostPath语法查询
kubectl explain pods.spec.volumes.hostPath
| 属性名称 | 类型 | 是否必选 | 取值说明 |
|---|---|---|---|
| path | string | required | 主机上目录的路径。如果路径是符号链接,它将链接到真实路径。 |
| type | string | 主机默认卷的类型。可选值: ● DirectoryOrCreate:如果指定的目录不存在,就自动创建一 个空目录,权限设置为0755,与kubelet具有相同的组和所有权。 ● Directory:表示将使用现有主机上的目录。给定的目录必须 存在。 ● FileOrCreate:如果在主机上指定的文件不存在,则创建一个 该空文件,权限设置为0644,与kubelet具有相同的组和所有权。 否则将使用现有文件。 ● File:表示将使用现有主机上的文件。给定的文件必须存在。 ● Socket:表示使用主机上的Unix套接字文件。必须存在。 ● CharDevice:表示使用主机上的字符设备文件。必须存在。 ● BlockDevice:表示使用主机上的块设备文件。必须存在。 |
**实战: 创建一个Pod挂载工作节点的/data1目录,如果目录不存在就创建。 测试删除Pod,目录的数据是否会丢失。 **
//创建资源清单文件
vi hostpath.yaml
apiVersion: v1
kind: Pod
metadata:
name: test-hostpath # Pod 名称
spec:
containers:
- name: test-nginx # 第一个容器:Nginx
image: nginx # 使用 nginx 镜像
volumeMounts:
- name: test-volume # 挂载的卷名称
mountPath: /test-nginx # 挂载到容器内的路径
- name: test-tomcat # 第二个容器:Tomcat
image: tomcat:8.5-jre8-alpine # 使用 Tomcat 镜像
volumeMounts:
- name: test-volume # 挂载的卷名称(与 Nginx 共享)
mountPath: /test-tomcat # 挂载到容器内的路径
volumes:
- name: test-volume # 定义存储卷名称
hostPath:
path: /data1 # 宿主机上的目录路径
type: DirectoryOrCreate # 如果目录不存在则自动创建
这个KubernetesPod的YAML配置,演示了如何在Pod中使用hostPath持久化存储卷,并将其挂载到多个容器中。
在这个示例中,spec.volumes中声明了一个名为test-volume的hostPath存储卷,它用的路径为/data1,并且指定了类型为DirectoryOrCreate。这意味着如果在主机上指定
的目录不存在,则会在主机上创建该目录。否则,Kubernetes将使用现有目录。
然后,在spec.containers中声明了两个容器,并在每个容器中都挂载了test-volume储卷。test-nginx容器将卷挂载到/test-nginx目录下,而test-tomcat容器则将卷挂载
到/test-tomcat目录下。
需要注意的是,在使用hostPath持久化存储卷时,需要小心不要不小心地将敏感数据暴露到Pod中,因为它直接暴露了节点的文件系统。此外,当Pod迁移到其他节点时,这个
目录映射不会跟随迁移而改变,因此可能会影响到应用程序的可移植性。
//更新资源清单文件
kubectl apply -f hostpath.yaml
//查看pod调度到了哪个物理节点
kubectl get pods -o wide
//创建临时数据、测试容器内是否同步、在对应的节点执行
//1.在对应节点执行
ll -d /data1/
cd /data1/
echo "I am xxx" > name.txt
cat name.txt
//2.登录到test-hostpath pod下的test-nginx容器、检查创建的文件是否存在
kubectl exec -it test-hostpath -c test-nginx --/bin/bash
cd /test-nginx/
ls
catname.txt
//3.登录到test-hostpath pod下的test-tomcat容器,检查创建的文件是否存在
kubectl exec -it test-hostpath -c test-tomcat --/bin/bash
cd /test-tomcat/
ls
cat name.txt
上面测试可以看到、同一个pod里的test-nginx和test-tomcat这两个容器是共享存储卷的
hostpath存储卷缺点:单节点、pod删除之后重新创建必须调度到同一个nod节点、数据才不会丢失
//删除pod、检查数据是否还在
kubectl delete -f hostpath.yaml
//检查数据是否还在
ll -d /data1/
ls /data1/ -l
cat /data1/name.txt
//注意点:若生产使用hostPath挂载方式,必须指定nodeName,否则pod删除掉之后,
下次再创建pod,不一定能百分百调度到之前的node节点上
apiVersion: v1
kind: Pod
metadata:
name: test-hostpath # Pod名称
spec:
nodeName: k8s-node02 # 指定调度到k8s-node02节点
containers:
- name: test-nginx # 第一个容器:Nginx
image: nginx # 使用官方nginx镜像
volumeMounts:
- name: test-volume # 引用的存储卷名称
mountPath: /test-nginx # 挂载到容器内的路径
- name: test-tomcat # 第二个容器:Tomcat
image: tomcat:8.5-jre8-alpine # 使用Tomcat镜像(Alpine精简版)
volumeMounts:
- name: test-volume # 引用的存储卷名称(与Nginx共享)
mountPath: /test-tomcat # 挂载到容器内的路径
volumes:
- name: test-volume # 定义存储卷
hostPath:
path: /data1 # 宿主机上的绝对路径
type: DirectoryOrCreate # 目录不存在时自动创建
# 其他可选类型:
# Directory - 必须已存在的目录
# File - 必须已存在的文件
# Socket - 必须已存在的Unix socket
4.k8s持久化存储nfs
由于hostPath存储存在单点故障、pod挂载hostpath时、只有调度到同一个节点数据才不会丢失、使用nfs作为持久化存储可以避免这些问题。
NFS是一种分布式文件系统协议、允许计算机之间共享文件和目录,在k8s之中、可以使用NFS作为一种持久化存储卷类型、使得多个pod之间可以共享相同的数据
在使用NFS存储卷时、需要先安装NFS服务器、并创建一个共享目录、在创建pod时、可以直接将NFS共享的目录挂载到容器内。
其实相对而言,nfs也是不够安全的,也是存在单点故障,我们可以采用对接分布式文件存储来实现存储高可用。这些我们后面会讲到。
NFS参数解释如下
| 属性名称 | 取值类型 | 是否必选 | 取值说明 |
|---|---|---|---|
| path | string | required | NFS 服务器共享的目录。 |
| readOnly | boolean | 此处readOnly如果设置为true时,将强制NFS以只读权限挂载。 默认为false。 | |
| server | string | required | NFS 服务器的主机名或IP地址 |
**实战: 使用nfs共享/data/volumes目录并挂载到Pod内。测试删除Pod, 目录的数据是否会丢失。 **
//以k8s的控制节点作为NFS服务端(所有k8s工作节点都需要安装这个包,否则pod无法挂载nfs)
//安装nfs
yum install nfs-utils -y
//创建nfs需要共享的目录
mkdir /data/volumes -p
//配置nfs共享服务器、共享/data/volumes目录
vi /etc/exports
/data/volumes192.168.128.0/24(rw,no_root_squash)
#no_root_squash:用户具有根目录的完全管理访问权限
//启动nfs服务
systemctl enable nfs-server.service --now
//在k8s-node-01节点上手动挂载nfs共享目录测试
mkdir /test
mount 192.168.128.11 : /data/volumes/test
df -Th | grep test
umount /test/
//创建资源清单文件
vi nfs.yaml
apiVersion: v1 # Kubernetes API 版本
kind: Pod # 资源类型为 Pod
metadata:
name: test-nfs-volume # Pod 名称
spec:
containers:
- name: test-nfs # 容器名称
image: nginx # 使用官方 nginx 镜像
imagePullPolicy: IfNotPresent # 镜像拉取策略:本地已有则不重新拉取
ports:
- containerPort: 80 # 容器暴露的端口
protocol: TCP # 使用 TCP 协议
volumeMounts:
- name: nfs-volumes # 挂载的卷名称(需与下方volumes匹配)
mountPath: /usr/share/nginx/html # 挂载到容器内的路径
volumes:
- name: nfs-volumes # 卷名称
nfs:
path: /data/volumes # NFS 服务器上的共享路径
server: 192.168.128.11 # NFS 服务器 IP 地址
这是一个使用NFS持久化存储卷的KubernetesPod配置文件示例。具体来说,这个Pod
会在容器中使用nginx镜像作为Web服务器,并将NFS存储卷挂载到/usr/share/nginx/html
目录下。
其中,spec.containers中定义了一个名为test-nfs的容器,并指定了nginx镜像。
该容器监听了80端口,并将该端口暴露给其他Pod。
spec.volumes中定义了一个名为nfs-volumes的持久卷,并在其中使用nfs指定NFS
服务器的地址、共享目录的路径。在这个例子中,nfs.server指向IP地址为192.168.128.11
的NFS服务器,而nfs.path则为共享目录的路径/data/volumes。
最后,在spec.containers.volumeMounts中将该NFS存储卷挂载到了容器中的
/usr/share/nginx/html目录下,以提供持久性存储。
//更新资源清单文件
kubectl apply -f nfs.yaml
//查看创建的pod
kubectl get pods test-nfs-volume -o wide
//登录到nfs服务器、在共享目录创建一个index.html
cd /data/volumes/
echo"My Name is xxx" > index.html
cat index.html
//进入pod、查看
kubectl exec -it test-nfs-volume --/bin/bash
cd /usr/share/nginx/html/
ls
cat index.html
//请求pod、测试(注意替换地址)
curl 10.244.85.198
经过上面测试说明挂载nfs存储卷成功了,nfs支持多个客户端挂载,可以
创建多个pod,挂载同一个nfs服务器共享出来的目录;但是nfs如果宕机了,
数据也就丢失了,所以需要使用分布式存储,常见的分布式存储有glusterfs
和cephfs
//清除pod
kubectl delete -f nfs.yaml
//查看数据是否被清除
ls /data/volumes/
cat /data/volumes/index.html
5.k8s持久化存储pv与pvc
简化版:PV(PersistentVolume)与PVC(PersistentVolumeClaim)基本概念及工作原理
PV(PersistentVolume)
- 定义:Kubernetes中独立于Pod的持久化存储资源,可被多个Pod共享。
- 管理:由管理员创建,并通过PVC供Pod使用。
- 支持类型:如NFS、iSCSI、AWS EBS等。
- 功能:
- 配置存储类别、访问模式和容量。
- 实现数据持久化,即使Pod迁移或更新也能保留数据。
- 支持跨多个Pod的数据共享。
PVC(PersistentVolumeClaim)
- 定义:向Kubernetes申请特定需求的PV资源。
- 角色:作为Pod与实际存储之间的中介,声明所需存储大小及访问方式。
- 特性:
- 只能匹配同命名空间内的PV。
- 必须与PV规格完全匹配才能绑定。
- Kubernetes自动为PVC寻找合适的PV。
- 优点:
- 简化存储资源管理和使用。
- 减少Pod配置中的存储细节依赖,提高灵活性。
工作原理
- PV定义:管理员在控制台定义PV,指定存储类型、访问模式、容量等信息。
- PVC定义:用户创建PVC的yaml文件,定义所需的存储容量和访问模式。Kubernetes根据这些规范查找并匹配合适的PV。
- 绑定:用户创建PVC的yaml文件,在找到可用的pv之前、pvc会保持未绑定状态直至找到匹配的PV。绑定后,该PV不再可供其他PVC使用。若无合适PV,则PVC处于Pending状态。
- 挂载: 随着PVC和PV的绑定,管理员将把PV暴露给Kubernetes中的Pods。Pod 指定PVC名称,Kubernetes 确定哪个PVC绑定了哪个PV,并将PV添加到Pod 的文件系统中。Pod然后在容器中挂载PV,以使容器可以访问它。
- 回收策略: 当我们创建pod时如果使用pvc做为存储卷,那么它会和pv绑定,当删除 pod,pvc 和 pv绑定就会解除,解除之后和pvc绑定的pv卷里的数据需要怎么 处理,目前,卷可以保留,回收或删除:Retain、Recycle(不推荐使用,1.15 被废弃了)、Delete。
- Retain(默认):删除PVC时,PV仍存在但处于Released状态,不能被其他PVC使用,数据保留。
- Delete:删除PVC时,同时从Kubernetes移除PV,并从外部设施中删除存储资产。
综上所述,通过PVC和PV的协作,Kubernetes简化了存储资源的使用和管理过程,使得管理员可以专注于存储资源的定义,而开发人员则能够便捷地请求和使用这些资源。
pv与pvc语法与应用
pv字段说明
| 属性名称 | 取值类型 | 是否必选 | 取值说明 |
|---|---|---|---|
| accessModes | []string | 用于指定PV/PVC的访问模式。该字段可选的访问模式 包括: ● ReadWriteOnce(RWO):可被单个节点以读写方式 挂载。 ● ReadOnlyMany(ROX):可被多个节点以只读方式 挂载; ● ReadWriteMany(RWX):可被多个节点以读写方式 挂载。 针对不同的访问模式,PV对应的后端存储资源必须支 持相应的模式。下面是每种访问模式的更详细解释: ● ReadWriteOnce(RWO):该模式要求PV/PVC只能 被一个节点以读写方式挂载。这意味着,当PV/PVC与 Pod绑定时,Pod可以在一个节点上以读写模式使用该 PV/PVC,但不允许在其他节点上以相同方式使用。 ● ReadOnlyMany(ROX):该模式要求PV/PVC能够被 多个节点以只读方式挂载。这意味着,当PV/PVC与Pod 绑定时,Pod可以在多个节点上以只读模式使用该 PV/PVC,但不允许在任何一个节点上进行写操作。 ● ReadWriteMany(RWX):该模式要求PV/PVC可以 被多个节点以读写方式挂载。这意味着,当PV/PVC与 Pod绑定时,Pod可以在多个节点上以读写模式使用该 PV/PVC。 | |
| capacity | map[string] string | 用于指定PV或PVC的存储容量大小。该字段必须是以 字符串形式指定的数字,并附带相应的单位(如Gi、G、 Mi、M等)。 例如,要在PV上定义1GiB的存储容量,可以设置 spec.capacity.storage字段为1Gi。 | |
| persistentVolumeR eclaimPolicy | string | PersistentVolume.spec.persistentVolumeReclaimPo licy是指在删除使用完的PersistentVolume(PV)后, PV上残留的数据应该如何处理的策略。这个策略可以 在PV创建时指定。 可能用到的参数如下: ● Retain:保留PersistentVolume删除之后的数据, 不进行再利用。需要手动清理PV上的数据。 ● Recycle:自动清空PersistentVolume上面的数 据,PV又可以重复使用。可进行标准的文件系统格式 化和清空操作,但不适用于多个PV共享的场景。 ● Delete:直接删除PersistentVolume。PV上的数 据会被同步删除。 其中,默认的策略为Retain,即保留删除之后的数据。 在实际使用时,需要根据应用场景进行选择和配置。例如,对于One-Time使用的数据可以使用Delete策略, 对于需要保留数据并长期存储的应用可以使用Retain 策略。 |
pvc字段说明
| 属性名称 | 取值类型 | 是否必选 | 取值说明 |
|---|---|---|---|
| accessModes | []string | required | 指定访问模式 |
| resources | Object | required | 用于指定PV或PVC的存储容量大小。 |
| resources.limits | map[string]string | 限制允许请求的最大容量大小。 | |
| resources.requests | map[string]string | 请求所需的最小资源量。也就是最小容量。 | |
| storageClassName | string | storageClassName是声明所需的StorageClass 的名称 | |
| volumeMode | string | 用于指定PV和PVC的卷模式。卷模式决定了卷内 的内容如何被呈现给容器。 Kubernetes目前支持两种卷模式: ● Filesystem:该模式表示卷将被格式化为一 个文件系统,并作为常规挂载点提供给容器。这 是默认的卷模式。 ● Block:该模式表示卷被格式化为一个块设备 卷,通常用于需要性能较高且需要显式控制块设 备的应用程序。 | |
| volumeName | string | 用于引用现有的PersistentVolume(PV),即将 该PVC绑定到指定的PV上。 请求的访问模式和存储容量大小必须要和pv匹 配上,否则指定了PV进行绑定,也会绑定失败 |
然后在指定储存类型、例如: hostPath、nfs、cephfs、rbd等。
pv的yaml文件
//创建PV(这里使用nfs方式提供存储,使用上小节已经安装好的NFS)
//创建资源清单文件
vi pv.yaml
apiVersion: v1 # Kubernetes API 版本
kind: PersistentVolume # 资源类型为持久卷(PV)
metadata:
name: test # 持久卷名称
spec:
capacity:
storage: 5Gi # 存储容量为 5GB
accessModes:
- ReadOnlyMany # 访问模式:只读多节点挂载
nfs: # NFS 存储配置
path: /data/volumes # NFS 服务器上的共享路径
server: 192.168.128.11 # NFS 服务器 IP 地址
这个YAML文件定义了一个PV,在Kubernetes中,该PV将表示一个具有5G存储容量、只读多访问模式、NFS存储后端以及其它存储相关的特征。Kubernetes管理员只需将该PV
用于Pod容器即可。
需要注意的是,PV一旦创建并绑定到PVC上后,它的存储容量及访问模式就无法再进行更改。因此,在设置PV的时候需要仔细评估存储需求,并选择对应的存储类型与容量,
以满足业务需求。
//更新资源清单文件
kubectl apply -f pv.yaml
//查看pv
kubectl get pv
//输出说明
NAME:名称
CAPACITY:容量大小
ACCESSMODES:访问模式
RECLAIMPOLICY:资源回收策略
STATUS:资源状态,Available表示有空的,没有被PVC绑定。
CLAIM:由哪个供应商自动创建的PV
STORAGECLASS:存储类型
AGE:运行时间
pvc的yaml文件
//创建资源清单文件
vi pvc.yaml
apiVersion: v1 # Kubernetes API 版本
kind: PersistentVolumeClaim # 资源类型为持久卷声明(PVC)
metadata:
name: test-pvc # PVC 名称
spec:
accessModes:
- ReadOnlyMany # 访问模式:只读多节点挂载(需与PV匹配)
resources:
requests:
storage: 5Gi # 请求的存储容量为5GB(需小于等于PV容量)
根据这份配置文件,Kubernetes将在系统中为PVC创建5GiB的只读存储,并将其分配给Pod使用。注意,这里的PVC没有指定数据源,它会用默认的存储类provisioner来创建
PV,并将PV与PVC进行绑定
//更新资源清单文件
kubectl apply -f pvc.yaml
kubectl get pvc
//输出说明
NAME:PVC名称
STATUS:Bound表示此PVC已经和PV绑定;未绑定则为Pending状态。
VOLUME:绑定的PV名称
CAPACITY:卷的大小
ACCESSMODES:访问模式。
STORAGECLASS:存储类型
AGE:运行时间
//查看pv
kubectl get pv
挂载pvc给pod
** 目标:将上面创建好的pv和pvc挂载到pod内,测试删除pod数据是 否还在,pv和pvc是否有被删除。 **
//创建资源清单文件
cat pod-pvc.yaml
apiVersion: v1 # Kubernetes API 版本
kind: Pod # 资源类型为 Pod
metadata:
name: pod-pvc # Pod 名称
spec:
containers:
- name: nginx # 容器名称
image: nginx # 使用官方 nginx 镜像
volumeMounts:
- name: nginx-html # 挂载的卷名称(需与下方volumes匹配)
mountPath: /usr/share/nginx/html # 挂载到容器内的路径(nginx默认网页目录)
volumes:
- name: nginx-html # 卷名称
persistentVolumeClaim:
claimName: test-pvc # 引用的PVC名称(需与已存在的PVC名称一致)
//应用yaml文件
kubectl apply -f pod-pvc.yaml
//查看pod
kubectl get pods
//创建一个测试数据
cd /data/volumes/
ls
echo "This is test web" > index.html
//进入pod、测试挂载点是否可以读写
kubectl exec -it pod-pvc --bash
cd /usr/share/nginx/html/
ls
cat index.html
echo "I am xxx" > name.txt
ls
cat name.txt
//查看本地数据
ls /data/volumes/
cat /data/volumes/name.txt
//删除pod、查看数据是否还在、检查pvc状态
kubectl delete -f pod-pvc.yaml
ls /data/volumes/
kubectl get pv
kubectl get pvc
**实战: 从头开始安装NFS,创建10个PV,创建一个PVC,观察PV与PVC绑定的关系 **
//1.安装nfs
yum -y install nfs-utils
//2.创建nfs共享目录
mkdir /data/data_v{1..10} -p
ls /data/ -l
//3.修改nfs配置文件
vi /etc/exports
/data/data_v1192.168.128.0/24(rw,no_root_squash)
/data/data_v2192.168.128.0/24(rw,no_root_squash)
/data/data_v3192.168.128.0/24(rw,no_root_squash)
/data/data_v4192.168.128.0/24(rw,no_root_squash)
/data/data_v5192.168.128.0/24(rw,no_root_squash)
/data/data_v6192.168.128.0/24(rw,no_root_squash)
/data/data_v7192.168.128.0/24(rw,no_root_squash)
/data/data_v8192.168.128.0/24(rw,no_root_squash)
/data/data_v9192.168.128.0/24(rw,no_root_squash)
/data/data_v10192.168.128.0/24(rw,no_root_squash)
//4.启动nfs服务
systemctl restart nfs && systemctl enable nfs && systemctl status nfs
//5.检查
showmount -e 127.0.0.1
//创建pv资源清单文件
vi data-pv.yaml
---
# PV 1 - 1GB 单节点读写
apiVersion: v1
kind: PersistentVolume
metadata:
name: v1
spec:
capacity:
storage: 1Gi
accessModes:
- ReadWriteOnce # 单节点读写
nfs:
path: /data/data_v1
server: 192.168.128.11
---
# PV 2 - 2GB 多节点读写
apiVersion: v1
kind: PersistentVolume
metadata:
name: v2
spec:
capacity:
storage: 2Gi
accessModes:
- ReadWriteMany # 多节点读写
nfs:
path: /data/data_v2
server: 192.168.128.11
---
# PV 3 - 3GB 多节点只读
apiVersion: v1
kind: PersistentVolume
metadata:
name: v3
spec:
capacity:
storage: 3Gi
accessModes:
- ReadOnlyMany # 多节点只读
nfs:
path: /data/data_v3
server: 192.168.128.11
---
# PV 4 - 4GB 单节点或多节点读写
apiVersion: v1
kind: PersistentVolume
metadata:
name: v4
spec:
capacity:
storage: 4Gi
accessModes:
- ReadWriteOnce # 单节点读写
- ReadWriteMany # 多节点读写
nfs:
path: /data/data_v4
server: 192.168.128.11
---
# PV 5 - 5GB 单节点或多节点读写
apiVersion: v1
kind: PersistentVolume
metadata:
name: v5
spec:
capacity:
storage: 5Gi
accessModes:
- ReadWriteOnce
- ReadWriteMany
nfs:
path: /data/data_v5
server: 192.168.128.11
---
# PV 6 - 6GB 单节点或多节点读写
apiVersion: v1
kind: PersistentVolume
metadata:
name: v6
spec:
capacity:
storage: 6Gi
accessModes:
- ReadWriteOnce
- ReadWriteMany
nfs:
path: /data/data_v6
server: 192.168.128.11
---
# PV 7 - 7GB 单节点或多节点读写
apiVersion: v1
kind: PersistentVolume
metadata:
name: v7
spec:
capacity:
storage: 7Gi
accessModes:
- ReadWriteOnce
- ReadWriteMany
nfs:
path: /data/data_v7
server: 192.168.128.11
---
# PV 8 - 8GB 单节点或多节点读写
apiVersion: v1
kind: PersistentVolume
metadata:
name: v8
spec:
capacity:
storage: 8Gi
accessModes:
- ReadWriteOnce
- ReadWriteMany
nfs:
path: /data/data_v8
server: 192.168.128.11
---
# PV 9 - 9GB 单节点或多节点读写
apiVersion: v1
kind: PersistentVolume
metadata:
name: v9
spec:
capacity:
storage: 9Gi
accessModes:
- ReadWriteOnce
- ReadWriteMany
nfs:
path: /data/data_v9
server: 192.168.128.11
---
# PV 10 - 10GB 单节点或多节点读写
apiVersion: v1
kind: PersistentVolume
metadata:
name: v10
spec:
capacity:
storage: 10Gi
accessModes:
- ReadWriteOnce
- ReadWriteMany
nfs:
path: /data/data_v10
server: 192.168.128.11
//更新pv资源清单文件、并查看pv资源
kubectl apply -f data-pv.yaml
kubectl get pv
//创建pvc资源清单文件
cat data-pvc.yaml
apiVersion: v1 # Kubernetes API 版本
kind: PersistentVolumeClaim # 资源类型为持久卷声明(PVC)
metadata:
name: data-pvc # PVC 名称(需唯一,供Pod引用)
spec:
accessModes:
- ReadWriteMany # 访问模式:多节点读写(必须与目标PV模式匹配)
resources:
requests:
storage: 7Gi # 请求的存储容量(将绑定≥7Gi且模式匹配的PV)
//更新pvc资源清单文件
kubectl apply -f data-pvc.yaml
//查看资源
kubectl get pvc
kubectl get pv
可以看到pvc申请的访问模式为ReadWriteMany,pv v7的访问模式为ReadWriteOnce和ReadWriteMany,v7pv满足此pvc,他们绑定在一起之后,具
体的访问模式权限以PV为准
//创建pod、挂载pvc
vi data-pod.yaml
apiVersion: v1 # Kubernetes API 版本
kind: Pod # 资源类型为 Pod
metadata:
name: pod-pvc # Pod 名称(需唯一)
spec:
containers:
- name: nginx # 容器名称
image: nginx # 使用官方 nginx 镜像(默认 latest 标签)
imagePullPolicy: IfNotPresent # 镜像拉取策略(建议显式声明)
volumeMounts:
- name: nginx-html # 引用下方定义的卷名称
mountPath: /usr/share/nginx/html # 挂载到容器内的路径(nginx 默认网页目录)
readOnly: false # 读写模式(需与 PVC 的 accessModes 兼容)
volumes:
- name: nginx-html # 卷名称(需与 volumeMounts 对应)
persistentVolumeClaim:
claimName: data-pvc # 引用的 PVC 名称(必须已存在且处于 Bound 状态)
readOnly: false # 读写模式(默认可省略)
//更新资源清单文件
kubectl apply -f data-pod.yaml
//进入pod-pvc创建测试数据
kubectl exec -it pod-pvc --bash
cd /usr/share/nginx/html/
echo "hello, xiaozhang" >index.html
cat index.html
//删除pod、测试数据是否还在
kubectl delete -f data-pod.yaml
ls /data/data_v7/
cat /data/data_v7/index.html
//删除pvc测试
//删除pvc
kubectl delete -f data-pvc.yaml
//查看pvc状态
kubectl get pv
删除pvc之后,pv会处于released状态,想要继续使用这个pv,需要手动删除pv,kubectldeletepvpv_name,然后再重新创建此PV。
//查看数据是否还在
ls /data/data_v7/
//再次创建pvc、查看pvc状态
kubectl apply -f data-pvc.yaml
//查看pvc状态
kubectl get pvc
//查看pv状态
kubectlgetpv
//若是想要使用v7、则必须删除再创建
//重新创建所有pv和pvc
kubectl delete -f data-pvc.yaml
kubectl delete -f data-pv.yaml
kubectl apply -f data-pv.yaml
kubectl apply -f data-pvc.yaml
//查看pv
kubectl get pv
//查看pvc
kubectl get pvc
//查看数据
ls /data/data_v7/
cat /data/data_v7/index.html
为什么删除pv时、数据不会丢失
因为默认回收策略是Retain(保留),所以数据不会被删除
使用pv和pvc的注意事项
注意:使用pvc和pv的注意事项 1、我们每次创建pvc的时候,需要事先有划分好的pv,这样可能不方便, 那么可以在创建pvc的时候直接动态创建一个pv这个存储类,pv事先是不存在 的。 2、pvc和pv绑定,如果使用默认的回收策略retain,那么删除pvc之后, pv会处于released状态,我们想要继续使用这个pv,需要手动删除pv,kubectl delete pv pv_name,删除pv,不会删除pv里的数据,当我们重新创建pvc时 还会和这个最匹配的pv绑定,数据还是原来数据,不会丢失。
6.k8s存储类storageclass
如果pvc请求数量太多、对于运维人员维护成本会很高、K8s提供一种自动创建pv的机制、就是storageClass、他的作用是创建pv的模板、k8s集群管理员通过创建storageClass可以动态生成一个存储卷pv供K8spvc使用
StorgaeClass会定义一下两部分
1、PV 的属性,比如存储的大小、类型等。
2、创建这种PV需要使用到的存储插件,比如Ceph、NFS等。 有了这两部分信息,Kubernetes就能够根据用户提交的PVC,找到对应的 StorageClass,然后 Kubernetes 就会调用StorageClass 声明的存储插件,创建 出需要的PV。
storageclass语法说明
provisioner
每个StorageClass都有一个制备器(provisioner),provisioner用来确定我们使用什么样的存储来创建pv,常见的provisioner如下: provisioner打对勾的表示可以由内部供应商提供,也可以由外部供应商提供
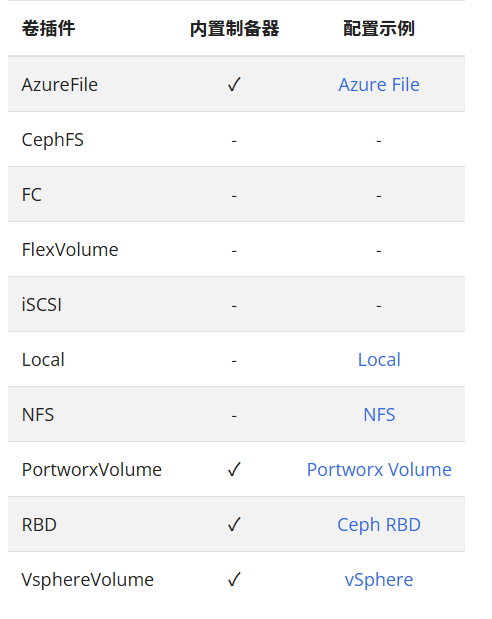
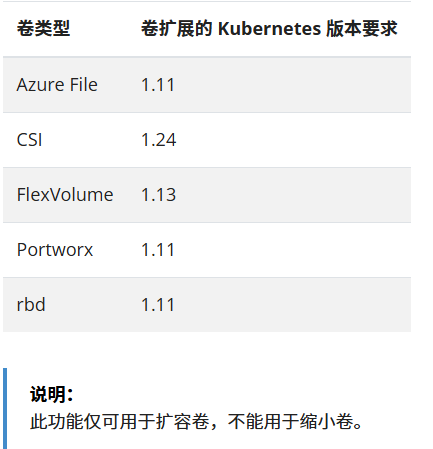
**allowVolumeExpansion字段说明: **
allowVolumeExpansion:允许卷扩展,PersistentVolume可以配置成可扩展。将此功能设置为true时,允许用户通过编辑相应的PVC对象来调整卷大小。 以下类型的卷支持卷扩展:
storageclass整体语法
| 属性名称 | 取值类型 | 是否必选 | 取值说明 |
|---|---|---|---|
| allowVolumeExpansion | boolean | 指定了存储卷是否可以动态扩展其容量。这意味着 如果存储卷的容量已经满了,可以通过修改 StorageClass的请求容量来扩展现有的存储卷的容 量,而不必创建一个新的存储卷。 扩展存储卷的能力取决于底层存储插件是否支持扩 容,以及存储卷所连接的节点上是否有足够的可用 存储资源。 | |
| allowedTopologies | []Object | 指定了存储卷可以被动态分配的节点拓扑域。 示例: apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: standard provisioner: kubernetes.io/gce-pd parameters: type: pd-standard volumeBindingMode: WaitForFirstConsumer allowedTopologies:- matchLabelExpressions:- key: kubernetes.io/hostname | |
| matchLabelExpressions.matchLabelExpressions.key | string | required | values:-k8s-node01-k8s-node02 这是一个Kubernetes的StorageClass的yaml文 件,属性包括: ● volumeBindingMode:WaitForFirstConsumer 表示存储卷的绑定模式为Waiting。即等待Pod被 调度到节点上再绑定存储卷。 ● allowedTopologies:表示存储卷可以被动态分 配的节点拓扑域。 ● matchLabelExpressions:表示节点拓扑域的匹 配。这里使用的是matchLabelExpressions来匹配 节点。 ● key:kubernetes.io/hostname表示匹配的节 点标签。 ● values:表示匹配标签值的节点是k8s-node01 和k8s-node02 |
| matchLabelExpressions.matchLabelExpressions.values | []string | required | 指定了Kubernetes如何绑定动态分配的存储卷。 Kubernetes中存在两种存储卷绑定模式: ● Immediate模式:在创建Pod的过程中立即绑 定存储卷。若使用此模式,应设置值为 “Immediate”。 ● Waiting模式:等待Pod被调度到节点上,然 后再绑定存储卷。若使用此模式,应设置值为 “WaitForFirstConsumer”。 默认情况下,Kubernetes使用Immediate模式来绑 定动态分配的存储卷。这意味着在创建Pod时,存 储卷将会立即被绑定并用于该Pod。然而,在某些 情况下,可能需要使用Waiting模式来等待Pod被 调度到节点上再绑定存储卷。例如,如果使用的存 储插件需要等到Pod被调度到指定的节点上,才能 将存储卷绑定到Pod上 |
| volumeBindingMode | string | string | |
| provisioner | string | string | provisioner用来确定我们使用什么样的存储来创 建pv。 |
| reclaimPolicy | string | string | 定义Persistent Volume(PV)的回收策略,当该 PV被释放时是否要对其进行清除操作。 可以设置以下三种回收策略: ● Retain:保留存储资源,当PV释放时不会执行 清除操作,需要手动清理对应的存储资源。 ● Delete:在PV释放时将其对应的存储资源删 除,并释放存储区块。 ● Recycle:PV的回收策略为回收并重用PV。 |
**实战:使用NFS provisioner动态生成PV **
NFS-Subdir-External-Provisioner 是 Kubernetes 中的一个应用程序,它可以自动为 一个或多Kubernetes Persistent Volume Claims(PVCs)创建 NFS共享,并将它们挂载 到相应的Pod中。这个程序主要是为了解决Kubernetes环境中动态PV创建的问题。使用这 个程序可以大大降低PV的管理配置工作量。
该程序通过监控Kubernetes的StorageClasses和PersistentVolumeClaims 资源,自 动创建和删除PersistentVolum 资源。这个程序使用了NFS共享服务器提供的卷。当一个 PVC 请求被创建时,该程序会新建一个与其相容的PV,并将其插入到KubernetesPersistent Volume 树中。当PVC资源被删除时,将会自动删除PV资源。
GitHub 地址:(下面部署皆参考此) https://github.com/kubernetes-sigs/nfs-subdir-external-provisioner
//安装nfs provisioner
yum install nfs-utils -y
//创建nfs需要的共享目录
mkdir /nfs/data -p
//配置nfs共享服务器,共享/data/volumes目录
vi /etc/exports
/nfs/data 192.168.128.0/24(rw,no_root_squash)
# no_root_squash: 用户具有根目录的完全管理访问权限
//启动nfs服务
systemctl restart nfs-server && systemctl enable nfs-server && systemctl status nfs-server
//创建运行nfs-provisioner需要的sa账号
vi nfs-serviceaccount.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: nfs-client-provisioner # ServiceAccount 名称,需与后续资源(如 Deployment)引用一致
namespace: default # 部署的命名空间,根据实际环境修改(如 kube-system 或自定义命名空间)
annotations:
# 可选:添加维护信息注释(参考网页6/网页8的元数据实践)
maintainer: "devops-team@example.com"
description: "ServiceAccount for NFS Client Provisioner"
这是一个Kubernetes ServiceAccount的YAML文件,用于创建一个名为nfs-client-provisioner的服务帐户,并将其部署到名为default的命名空间
中。
//应用yaml文件
kubectl apply -f nfs-serviceaccount.yaml
//扩展:什么是sa
sa的全称是serviceaccount。
serviceaccount是为了方便Pod里面的进程调用KubernetesAPI或其他外部服务而设计的。
在创建Pod的时候指定serviceaccount,那么当Pod运行后,他就拥有了我们指定账号的权限了
//对sa授权
vi nfs-rbac.yaml
---
# ClusterRole 定义 NFS 客户端供应器所需的集群级权限
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: nfs-client-provisioner-runner
rules:
- apiGroups: [""]
resources: ["nodes"]
verbs: ["get", "list", "watch"] # 允许读取节点信息
- apiGroups: [""]
resources: ["persistentvolumes"]
verbs: ["get", "list", "watch", "create", "delete"] # 管理 PV 生命周期
- apiGroups: [""]
resources: ["persistentvolumeclaims"]
verbs: ["get", "list", "watch", "update"] # 管理 PVC 状态
- apiGroups: ["storage.k8s.io"]
resources: ["storageclasses"]
verbs: ["get", "list", "watch"] # 读取 StorageClass 配置
- apiGroups: [""]
resources: ["events"]
verbs: ["create", "update", "patch"] # 记录事件日志
---
# ClusterRoleBinding 将 ClusterRole 绑定到 ServiceAccount
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: run-nfs-client-provisioner
subjects:
- kind: ServiceAccount
name: nfs-client-provisioner # 绑定的服务账户名称
namespace: default # 服务账户所在命名空间
roleRef:
kind: ClusterRole
name: nfs-client-provisioner-runner # 引用的 ClusterRole 名称
apiGroup: rbac.authorization.k8s.io
---
# Role 定义 NFS 客户端供应器在特定命名空间的权限(用于领导者选举)
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-locking-nfs-client-provisioner
namespace: default # 作用范围限定在 default 命名空间
rules:
- apiGroups: [""]
resources: ["endpoints"]
verbs: ["get", "list", "watch", "create", "update", "patch"] # 管理 endpoints 实现分布式锁
---
# RoleBinding 将 Role 绑定到 ServiceAccount
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-locking-nfs-client-provisioner
namespace: default # 必须与 Role 的命名空间一致
subjects:
- kind: ServiceAccount
name: nfs-client-provisioner # 绑定的服务账户名称
namespace: default # 服务账户所在命名空间
roleRef:
kind: Role
name: leader-locking-nfs-client-provisioner # 引用的 Role 名称
apiGroup: rbac.authorization.k8s.io
首先是一个ClusterRoleYAML文件,它定义了nfs-client-provisioner-runner角色,可以访问一些资源,比如节点、持久化卷、持久化卷声明、存储类和事件,并且可以执行查
看和监听操作。除此之外还可以创建、删除、更新、补丁操作和更新PV。接下来是一个ClusterRoleBinding YAML文件,它将上述角色绑定到
nfs-client-provisionerServiceAccount。
接下来是一个Role YAML文件,它定义了leader-locking-nfs-client-provisioner角色,该角色具有get、list、watch、create、update和patch操作的权限。
接下来,是一个RoleBindingYAML文件,它将上述角色绑定到nfs-client-provisionerServiceAccount
//应用yaml文件
kubectl apply -f nfs-rbac.yaml
//安装nfs-provisioner程序
vi nfs-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nfs-client-provisioner # Deployment 名称
labels:
app: nfs-client-provisioner # 用于 Pod 选择器的标签
namespace: default # 部署的目标命名空间
spec:
replicas: 1 # 单副本运行(避免 PV 冲突)
strategy:
type: Recreate # 使用重建策略(确保 PV 独占访问)
selector:
matchLabels:
app: nfs-client-provisioner # 匹配 Pod 标签
template:
metadata:
labels:
app: nfs-client-provisioner # Pod 标签(需与 selector 一致)
spec:
serviceAccountName: nfs-client-provisioner # 关联的 ServiceAccount
containers:
- name: nfs-client-provisioner
image: registry.cn-hangzhou.aliyuncs.com/lfy_k8s_images/nfs-subdir-external-provisioner:v4.0.2 # 官方 NFS 供应器镜像
# resources: # 资源限制(示例,当前注释)
# limits:
# cpu: 10m
# requests:
# cpu: 10m
volumeMounts:
- name: nfs-client-root
mountPath: /persistentvolumes # NFS 挂载到容器的路径
env:
- name: PROVISIONER_NAME # 供应器标识(需与 StorageClass 的 provisioner 字段匹配)
value: kubernetes.test/nfs
- name: NFS_SERVER # NFS 服务器 IP 地址
value: 192.168.128.11
- name: NFS_PATH # NFS 服务器共享目录
value: /nfs/data
volumes:
- name: nfs-client-root
nfs:
server: 192.168.128.11 # NFS 服务器地址(需与 env 一致)
path: /nfs/data # NFS 共享目录路径
//应用yaml文件
kubectl apply -f nfs-deployment.yaml
//获取pod信息
kubectl get pods
//创建storageclass,动态供给pv
//创建资源清单文件
vi nfs-storageclass.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: nfs-storage # StorageClass 资源名称
provisioner: kubernetes.test/nfs # 必须与 Deployment 中 PROVISIONER_NAME 环境变量一致
parameters:
archiveOnDelete: "true" # 删除PV时保留数据(改为false则自动清理)
这个Kubernetes的YAML配置文件用来定义NFS存储类`nfs-storage`。metadata属性这里用来指定NFS存储类的名称为nfs-storage。
provisioner属性指定了用来提供持久化卷的插件名称,这里是kubernetes.test/nfs。
即使用刚刚部署的nfs-client-provisioner容器来提供持久化卷。parameters属性用来指定一些额外参数,这里使用了一个名为archiveOnDelete的参
数,将其值设置为true。这意味着当PVC被删除时,NFS服务器将会把存储的数据存档,而
不是直接删除。
//应用yaml文件
kubectl apply -f nfs-storageclass.yaml
//查看storageclass资源
kubectl get storageclass
//创建pvc、通过storageclass动态生成pv
//创建资源清单文件
vi nfs-pvc.yaml
//应用yaml文件
kubectl apply -f nfs-pvc.yaml
//查看是否动态生成了pv、pvc是否创建成功、并和pv绑定
kubectl get pvc
kubectl get pv
//查看NFS文件共享
ll /nfs/data/
这里的目录结构为:“命名空间-PVC名称-PV名称”。所以一般在生产环境中,我们一般创建PVC时,指定PVC的名称和Pod名称一样,就可以方便我们维
护。
//创建pod,挂载storageclass动态生成的pvc
//创建资源清单文件
vi nfs-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: nfs-test # Pod 名称
spec:
containers:
- name: nfs-test # 容器名称
image: nginx # 使用官方 nginx 镜像
volumeMounts:
- name: nfs-pvc # 挂载的卷名称
mountPath: /usr/share/nginx/html # 挂载到容器内的路径(nginx 默认网页目录)
restartPolicy: Never # Pod 退出后不自动重启(适合测试场景)
volumes:
- name: nfs-pvc # 卷定义名称
persistentVolumeClaim:
claimName: nfs-test-pvc # 引用的 PVC 名称(需与前面创建的 PVC 一致)
//更新资源清单文件
kubectl apply -f nfs-pod.yaml
//查看pod是否创建成功
kubectl get pods nfs-test
//创建测试数据
1.进入到pod中创建测试数据
kubectl exec -it nfs-test --/bin/sh
#cd /usr/share/nginx/html
#echo"This istestweb"> index.html
2.查看nfs共享目录下的数据
ls /nfs/data/default-nfs-test-pvc-pvc-a9111d19-3dde-4bba-b2e0-1e5eb71a0cde/
//删除pod和pvc
kubectl delete -f nfs-pod.yaml
kubectl delete -f nfs-pvc.yaml
//查看pv
kubectl get pv
//进入到共享目录中、会发现、目录前加了archived
1.查看nfs共享目录下的文件
cd /nfs/data/
ls
3.进入到目录中查看数据
可以发现数据是没有被删除的。如果过时的数据或者无用的数据,我们可以
手动去做清理。(自动清理风险太高)