
三.构建k8s多master多node
1、基本信息
创建三个主节点和2个从节点、在master-01和master-02上面部署nginx+keepalive实现节点高可用
用户访问的时候要访问vip地址、然后vip地址通过负载均衡转发到master、再到对应的pod
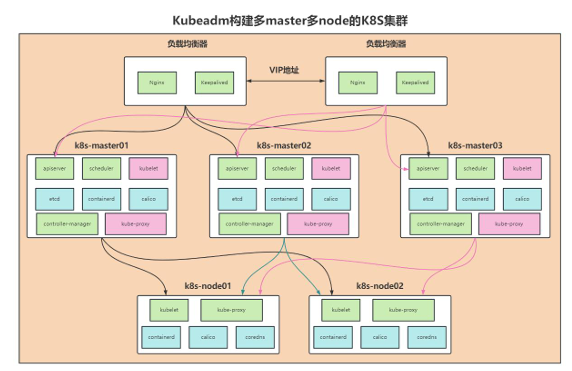
| 角色 | IP | 主机名 | 组件 | 硬件 |
|---|---|---|---|---|
| 控制节点 | 192.168.0.11 | k8s-master-01 | apiserver controller-manage scheduler etcd containerd keepalived+nginx calico kubelet kube-proxy | CPU: 4vVPU 硬盘:100GB 内存:4GB 开启虚拟化 |
| 控制节点 | 192.168.0.12 | k8s-master-02 | apiserver controller-manage scheduler etcd containerd keepalived+nginx calico kubelet kube-proxy | CPU: 4vVPU 硬盘:100GB 内存:4GB 开启虚拟化 |
| 控制节点 | 192.168.0.13 | k8s-master-03 | apiserver controller-manage scheduler etcd containerd calico kubelet kube-proxy | CPU: 4vVPU 硬盘:100GB 内存:4GB 开启虚拟化 |
| 工作节点 | 192.168.0.21 | k8s-node-01 | kubelet kube-proxy containerd calico coredns | CPU: 6vVPU 硬盘:100GB 内存:6GB 开启虚拟化 |
| 工作节点 | 192.168.0.22 | k8s-node-02 | kubelet kube-proxy containerd calico coredns | CPU: 6vVPU 硬盘:100GB 内存:6GB 开启虚拟化 |
2、安装k8s前的准备工作
0.给机器固定一个ip地址
vi /etc/sysconfig/network-scripts/ifcfg-ens33
TYPE=Ethernet
PROXY_METHOD=none
BROWSER_ONLY=no
BOOTPROTO=static
DEFROUTE=yes
IPV4_FAILURE_FATAL=yes
IPV6INIT=no
IPV6_AUTOCONF=no
IPV6_DEFROUTE=no
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=stable-privacy
NAME=ens33
UUID=9a45b75e-bb43-413e-b643-ee9c0365d04d
DEVICE=ens33
ONBOOT=yes
IPADDR=192.168.0.11
NETMASK=255.255.255.0
GATEWAY=192.168.0.1 \\这里的网关、子网掩码、dns要跟宿主机的一样
DNS1=192.168.1.1
DNS2=192.168.0.1
DNS3=8.8.8.8
1.配置机器主机名
// 分别在对应的机器上执行对应的指令更改机器主机名
hostnamectl set-hostname k8s-master-01 && bash
hostnamectl set-hostname k8s-master-02 && bash
hostnamectl set-hostname k8s-master-03 && bash
hostnamectl set-hostname k8s-node-01 && bash
hostnamectl set-hostname k8s-node-02 && bash
2.配置hosts解析
vi /etc/hosts
192.168.0.11 k8s-master-01
192.168.0.12 k8s-master-02
192.168.0.13 k8s-master-03
192.168.128.21 k8s-node-01
192.168.128.22 k8s-node-02
// 这里要重启一下
3.配置主机之间无密码登录
[root@k8s-master01~]#ssh-keygen
[root@k8s-master01~]#ssh-copy-id k8s-master-01
[root@k8s-master01~]#ssh-copy-id k8s-master-02
[root@k8s-master01~]#ssh-copy-id k8s-master-03
[root@k8s-master01~]#ssh-copy-id k8s-node-01
[root@k8s-master01~]#ssh-copy-id k8s-node-02
4.关闭交换分区swap、提升性能
1.临时关闭Swap(立即生效)
sudo swapoff -a # 关闭所有活跃的Swap分区或文件
2.永久禁用Swap挂载
sudo sed -i '/swap/s/^/#/' /etc/fstab # 一键注释所有包含"swap"的行
手动操作:若需精细控制,可用文本编辑器(如vim)打开文件,找到类似 /dev/mapper/cl-swap swap swap defaults 0 0 的行,行首添加#注释。
3.重启系统生效
sudo reboot # 重启后Swap将不再自动启用
4.验证
free -m | grep Swap # 输出应为 "Swap: 0 0 0"
swapon --show # 无输出表示无活跃Swap
为什么要关闭swap交换分区
swap是交换分区,如果机器内存不够,会使用swap分区,但是swap分区 的性能较低,k8s设计的时候为了能提升性能,默认是不允许使用swap分区的。 kubeadm初始化的时候会检测swap是否关闭,如果没关闭,那就初始化失败。 如果不想要关闭交换分区,安装k8s的时候可以指定--ignore-preflight-errors=swap来解决。
5.修改机器内核参数
# 1. 加载内核模块(立即生效)
modprobe br_netfilter
modprobe overlay
modprobe nf_conntrack
# 2. 配置模块开机自动加载(替代写入/etc/profile的方案)
cat > /etc/modules-load.d/k8s.conf <<EOF
br_netfilter
overlay
nf_conntrack
EOF
# 3. 配置内核参数文件
cat > /etc/sysctl.d/k8s.conf <<EOF
net.bridge.bridge-nf-call-ip6tables=1
net.bridge.bridge-nf-call-iptables=1
net.ipv4.ip_forward=1
EOF
# 4. 应用内核参数(需先加载模块,否则会报错)
sysctl --system
这三条内核参数配置必须设置、否则在初始化k8s集群的时候、会报错
6.关闭firewalld防火墙
systemctl stop firewalld;systemctl disable firewalld
7.关闭selinux
sudo sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config
8.配置阿里云repo源
备份原有仓库文件
mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup
下载阿里云centos7仓库文件
curl -o /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo
清理缓存并重建元数据
yum clean all
yum makecache
安装必要工具(如 wget)
yum install -y wget
yum -y install lrzsz net-tools
9.配置时间同步
# 设置时区
timedatectl set-timezone Asia/Shanghai
# 安装 Chrony
yum -y install chrony
# 配置 Chrony(使用阿里云 NTP 源)
cat > /etc/chrony.conf <<EOF
server time1.aliyun.com iburst
server time2.aliyun.com iburst
driftfile /var/lib/chrony/drift
makestep 1.0 3
rtcsync
logdir /var/log/chrony
EOF
# 重启服务并验证
systemctl restart chronyd
systemctl enable chronyd
# 验证配置
chronyc sources -v
//这里能看到具体的时间
systemctl status chronyd
10.开启ipvs
// 直接把下面的一大段复制到命令行运行就可以了
#!/bin/bash
# 定义IPVS模块及依赖检查项
ipvs_modules=(ip_vs ip_vs_rr ip_vs_wrr ip_vs_sh nf_conntrack)
check_modules=(ip_vs ip_vs_rr ip_vs_wrr ip_vs_sh nf_conntrack libcrc32c)
# 加载模块
for module in "${ipvs_modules[@]}"; do
if ! lsmod | grep -q "^${module}"; then
if modprobe -v "$module"; then
echo "[OK] Module $module loaded"
else
echo "[ERROR] Failed to load $module. Check dmesg:"
dmesg | grep -i "$module" | tail -n 3
exit 1
fi
else
echo "[INFO] $module already loaded"
fi
done
# 持久化配置
echo "Persisting modules..."
echo -e "ip_vs\nip_vs_rr\nip_vs_wrr\nip_vs_sh\nnf_conntrack" | sudo tee /etc/modules-load.d/ipvs.conf >/dev/null
# 综合校验
echo "=== Validation Report ==="
echo "1. Loaded Modules:"
lsmod | grep -E '^ip_vs|^nf_conntrack|^libcrc32c'
echo "2. Dependency Check:"
for mod in "${check_modules[@]}"; do
lsmod | grep -q "^$mod" && status="✔" || status="✘"
echo " $mod $status"
done
echo "3. Kernel Log Summary:"
dmesg | grep -i -A2 -B2 'ip_vs\|nf_conntrack'
ipvs是什么
** **ipvs(IP Virtual Server)实现了传输层负载均衡,也就是我们常说的4 层LAN交换,作为Linux内核的一部分。ipvs运行在主机上,在真实服务器集 群前充当负载均衡器。ipvs可以将基于TCP和UDP的服务请求转发到真实服务 器上,并使真实服务器的服务在单个IP地址上显示为虚拟服务。
ipvs和iptable对比
ipvs模式,在v1.9中处于beta阶段,在v1.11中已经正式可用了。iptables 模式在v1.1中就添加支持了,从v1.2版本开始iptables就是kube-proxy默认 的操作模式,ipvs和iptables都是基于netfilter的,但是ipvs采用的是hash 表,因此当service数量达到一定规模时,hash查表的速度优势就会显现出来, 从而提高service的服务性能。那么ipvs模式和iptables模式之间有哪些差异 呢?
- ipvs 为大型集群提供了更好的可扩展性和性能
- ipvs 支持比iptables更复杂的复制均衡算法(最小负载、最少连接、 加权等等)
- ipvs 支持服务器健康检查和连接重试等功能
11.安装基础软件包
# 安装基础工具
sudo yum install -y wget net-tools nfs-utils lrzsz vim ncurses-devel telnet unzip
# 安装开发工具链(替代手动枚举 gcc/make 等)
sudo yum groupinstall -y "Development Tools"
# 安装依赖库与安全组件
sudo yum install -y libxml2-devel openssl-devel curl-devel zlib-devel libaio-devel openssh-server socat
# 安装容器与集群工具
sudo yum install -y yum-utils device-mapper-persistent-data lvm2 ipvsadm conntrack
# 启用 EPEL 仓库
sudo yum install -y epel-release
# 重建缓存(避免后续安装报错)
sudo yum clean all && sudo yum makecache
3、构建k8s多masrer多node集群
1.安装k8s 需要的软件包源
#更换repo源(这个是1.28版本的k8s、新版本可以去https://developer.aliyun.com/mirror/kubernetes网页查看)
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
setenforce 0
// 安装 k8s需要的软件包 (下面的kuberlet kubeadm kubectl都是1.28.2版本的)
yum install -y kubelet kubeadm kubectl
systemctl enable kubelet && systemctl start kubelet
# 清理缓存并重建元数据(顺序不可颠倒)
yum clean all && yum makecache
# 验证仓库列表(检查是否包含 Kubernetes)
yum repolist | grep -i kubernetes
每个软件包的作用
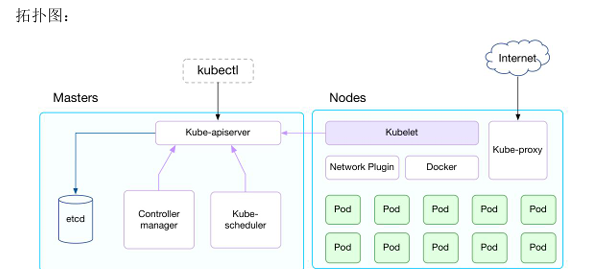
- kubelet:kubelet是Kubernetes集群中的一个核心组件,是每个节点上的 代理服务,负责与主控制节点通信,管理节点上的Pod和容器。kubelet的主要职责包括: 监控pod的状态并按需启动或停止容器、检查容器是否正常运行、与主控制 节点通信,将节点状态和Pod状态上报给主控制节点、管理容器的生命周期,包 括启动、停止、重启等、拉取镜像。
- kubeadm kubeadm:用于初始化、升级k8s集群的命令行工具。
- kubectl kubectl:用于和集群通信的命令行,通过kubectl可以部署和管理应用, 查看各种资源,创建、删除和更新各种组件
2.部署containerd容器
//安装containerd
sudo yum install -y containerd
//设置容器运行时为containerd
sudo mkdir -p /etc/containerd
containerd config default | sudo tee /etc/containerd/config.toml
//修改containerd配置文件
vi /etc/containerd/config.toml
//下面有三个需要修改的地方、修改用蓝色、增加用紫色
//1.配置 Sandbox 镜像为国内镜像源(Kubernetes Pod 基础容器)
sandbox_image = "registry.aliyuncs.com/google_containers/pause:3.6"
[plugins."io.containerd.grpc.v1.cri".registry.mirrors]
// 2.下面是是新增加的docker镜像加速和k8s镜像加速
[plugins."io.containerd.grpc.v1.cri".registry.mirrors."docker.io"]
endpoint = [
"https://docker.1ms.run",
"https://registry.cn-hangzhou.aliyuncs.com",
"https://hub-mirror.c.163.com"
]
[plugins."io.containerd.grpc.v1.cri".registry.mirrors."k8s.gcr.io"]
endpoint = [
"registry.aliyuncs.com/google_containers",
"docker.nju.edu.cn/google_containers",
"registry.cn-hangzhou.aliyuncs.com/google_containers"
]
3.修改SystemdCgroup = true、原值为false
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options]
BinaryName = ""
CriuImagePath = ""
CriuPath = ""
CriuWorkPath = ""
IoGid = 0
IoUid = 0
NoNewKeyring = false
NoPivotRoot = false
Root = ""
ShimCgroup = ""
SystemdCgroup = true
//应用
systemctl restart containerd && systemctl enable containerd && systemctl status containerd
3.keepalive+nginx实现k8s apiserver节点高可用(在三个主节点都执行)/也可以按需要只在master-01和master-02中执行
需要注意的是在keepalive的配置中、三个master节点依然需要区分为一个主节点和两个备节点、以确保vip的单一持有者、因此某些参数是不同的、比如优先级
需要注意的参数在代码块中用红色标识、新增的代码用蓝色标识
// 安装keepalive+nginx
yum install -y keepalived nginx nginx-mod-stream
//配置nginx代理
vi /etc/nginx/nginx.conf
user nginx;
worker_processes auto;
error_log /var/log/nginx/error.log;
pid /run/nginx.pid;
events {
worker_connections 1024;
}
stream {
log_format main '$remote_addr $upstream_addr - [$time_local] $status $upstream_bytes_sent';
access_log /var/log/nginx/k8s-access.log main;
upstream k8s-apiserver {
server 192.168.0.11:6443 max_fails=3 fail_timeout=30s;
server 192.168.0.12:6443 max_fails=3 fail_timeout=30s;
server 192.168.0.13:6443 max_fails=3 fail_timeout=30s;
}
server {
listen 16443;
proxy_pass k8s-apiserver;
proxy_timeout 60s;
proxy_connect_timeout 2s;
}
}
//keepalive配置
vi /etc/keepalived/keepalived.conf
global_defs {
router_id NGINX_MASTER_01 # 主备节点名称不能一样
vrrp_skip_check_adv_addr
script_user nobody
enable_script_security
}
vrrp_script check_nginx {
script "/etc/keepalived/check_nginx.sh"
interval 2
weight -20
fall 2
rise 1
}
vrrp_instance VI_1 {
state MASTER # 备节点改为 BACKUP
interface ens33
virtual_router_id 79 # 确保同一集群内的值是相同的、不同集群的值是不同的
priority 100 # 备节点设为 90
advert_int 1
#nopreempt # 备节点注释掉这个
authentication {
auth_type PASS
auth_pass 9T$9q#L9v!9m
}
virtual_ipaddress {
192.168.0.100/24 dev ens33
}
track_script {
check_nginx
}
}
//keepalived故障检测脚本
yum install -y nc # CentOS/RHEL 脚本里面使用了nc所以要安装一下
# 创建日志文件并设置权限
sudo touch /var/log/keepalived_nginx_check.log
sudo chown nobody:nobody /var/log/keepalived_nginx_check.log
sudo chmod 644 /var/log/keepalived_nginx_check.log
vi /etc/keepalived/check_nginx.sh
#!/bin/bash
LOG_FILE="/var/log/keepalived_nginx_check.log"
# 检查Nginx进程和端口
count=$(ps -C nginx --no-header | wc -l)
if [ $count -eq 0 ] || ! nc -z localhost 6443; then
echo "$(date '+%Y-%m-%d %H:%M:%S') - Nginx异常,尝试重启..." >> $LOG_FILE
systemctl restart nginx
sleep 2
# 二次检查
counter=$(ps -C nginx --no-header | wc -l)
if [ $counter -eq 0 ] || ! nc -z localhost 6443; then
echo "$(date '+%Y-%m-%d %H:%M:%S') - 重启失败,停止Keepalived..." >> $LOG_FILE
systemctl stop keepalived
exit 1
fi
fi
exit 0
//权限设置
chmod +x /etc/keepalived/check_nginx.sh
//启动服务并设置开机自启
systemctl restart nginx && systemctl enable nginx && systemctl status nginx
systemctl restart keepalived && systemctl enable keepalived && systemctl status keepalived
//查看ip是否生成
ip a
4.生成并修改初始化集群文件、初始化集群(从这里开始只是在master-01执行)
这里需要注意certSANs用于指定允许访问 API Server 的 IP 地址和域名列表。证书中必须包含所有可能的访问入口,否则客户端会因证书校验失败无法连接
一般是4种ip:所有 Master 节点的 IP、VIP(虚拟 IP)、Service 网段首个 IP、DNS 名称(可选)
kubeadm config print init-defaults > init.default.yaml //生成初始化文件
vi init.default.yaml //修改这个文件
// 需要修改的地方用蓝色、增加的地方用紫色
apiVersion: kubeadm.k8s.io/v1beta3
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 192.168.0.11 //主节点、IP需与物理IP一致
bindPort: 6443 //kube-apiserver监听的地址
nodeRegistration:
criSocket: unix:///run/containerd/containerd.sock //路径需与容器运行时(containerd)的 socket 文件一致
imagePullPolicy: IfNotPresent
name: k8s-master-01 //主节点名称、需唯一,
taints: null
---
apiServer:
certSANs: //证书受信任的ip地址、可以多谢几个、方便后期扩展node节点
//虚拟ip(vip)
-192.168.0.100
//master节点ip
-192.168.0.11
-192.168.0.12
-192.168.0.13
//服务网段首个ip
-10.10.0.1 // 这里要确认一下服务网段的首个IP、Kubernetes 内部服务依赖此ip、缺失可能导致内部服务访问失败
//可选 DNS 名称、
- kubernetes
- kubernetes.default
- kubernetes.default.svc
- kubernetes.default.svc.cluster.local
- localhost
- 127.0.0.1
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta3
certificatesDir: /etc/kubernetes/pki //证书生成的位置
clusterName: kubernetes //集群名称
controllerManager: {}
dns: {}
etcd:
local:
dataDir: /var/lib/etcd // etcd的集群目录
imageRepository: registry.aliyuncs.com/google_containers //阿里云镜像加速避免拉取失败
kind: ClusterConfiguration
kubernetesVersion: 1.28.2 //需与 kubeadm、kubelet版本匹配
controlPlanEndpoint: 192.168.0.100:6443 //nginx负载均衡到kube-apiserver的入口地
networking:i
dnsDomain: cluster.local
serviceSubnet: 10.10.0.0/16 //需与网络插件(如 Calico/Flannel)配置一致
podSubnet: 10.244.0.0/16
scheduler: {}
---
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
mode: ipvs //使用IPVS负载均衡模式(需提前加载ip_vs模块
---
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
cgroupDriver: systemd // # 必须与容器运行时配置的 cgroup 驱动(systemd)一致
//预拉取镜像
kubeadm config images pull --config init.default.yaml
// 初始化集群、镜像不存在会拉取
kubeadm init --config=init.default.yaml

说明安装完成、需要把这三行语句执行一下、 配置kubectl的配置文件config,相当于对kubectl进行授权,这样kubectl 命令可以使用这个证书对k8s集群进行管理
kubeadm inir初始化流程分析
kubeadm在执行安装之前进行了相当细致的环境检测,下面看一看:
(1)检查执行init命令的用户是否为root,如果不是root,直接快速失败(failfast)。
(2)检查待安装的k8s版本是否被当前版本的kubeadm支持(kubeadm版本>=待安装
k8s版本)。
(3)检查防火墙,如果防火墙未关闭,提示开放端口10250。
(4)检查端口是否已被占用,6443(或你指定的监听端口)、10257、10259。
(5)检查文件是否已经存在,/etc/kubernetes/manifests/*.yaml。
(6)检查是否存在代理,连接本机网络、服务网络、Pod网络,都会检查,目前不允
许代理。
(7)检查容器运行时,使用CRI还是Docker,如果是Docker,进一步检查Docker服
务是否已启动,是否设置了开机自启动。
(8)对于Linux系统,会额外检查以下内容:
(8.1)检查以下命令是否存在:crictl、ip、iptables、mount、nsenter、ebtables、
ethtool、socat、tc、touch。
(8.2)检查/proc/sys/net/bridge/bridge-nf-call-iptables、
/proc/sys/net/ipv4/ip-forward内容是否为1。
(8.3)检查swap是否是关闭状态。
(9)检查内核是否被支持,Docker版本及后端存储GraphDriver是否被支持。对于
Linux系统,还需检查OS版本和cgroup支持程度(支持哪些资源的隔离)。
(10)检查主机名访问可达性。
(11)检查kubelet版本,要高于kubeadm需要的最低版本,同时不高于待安装的k8s
版本。
(12)检查kubelet服务是否开机自启动。
(13)检查10250端口是否被占用。
(14)如果开启IPVS功能,检查系统内核是否加载了ipvs模块。
(15)对于etcd,如果使用Localetcd,则检查2379端口是否被占用,/var/lib/etcd/
是否为空目录。如果使用Externaletcd,则检查证书文件是否存在(CA、key、cert),验
证etcd服务版本是否符合要求。
(16)如果使用IPv6,检查/proc/sys/net/bridge/bridge-nf-call-iptables、
/proc/sys/net/ipv6/conf/default/forwarding内容是否为1。
以上就是kubeadminit需要检查的所有项目了!
5.安装网络工具nerdctl-2.0.3-linux-amd64.tar.gz、节点加入集群并设置角色
1.先rz上传文件、安装nerdctl
tar xf nerdctl-2.0.2-linux-amd64.tar.gz //解压
mv nerdctl /usr/local/bin/
// 2.生成加入集群的token
kubeadm token create --print-join-command
//3拿得到的命令在node节点运行、就能加入集群了下面这句是例子、不要执行
kubeadm join 192.168.0.11:6443 --token ylqufq.192cv46r6g25b8c1 --discovery-token-ca-cert-hash sha256:2d22fa14e53e660c212e08df2e6ee2c7b15d069104081c52f76a1727f8b7b8e6
kubectl get nodes //1.查看集群节点
//4.设置role:、下面也是例子、不要执行、
kubectl label node [NAME] node-role.kubernetes.io/[ROLES]=
取消role:
kubectl label node [NAME] node-role.kubernetes.io/[ROLES]-
查询role:
kubectl get nodes
例子
kubectl label node k8s-node01 node-role.kubernetes.io/worker=worker
kubectl label node k8s-node01 node-role.kubernetes.io/worker-
6.安装helm
下载helm并上传到master节点、解压、安装
安装 Helm
tar -zxvf helm-v3.16.4-linux-amd64.tar.gz
sudo mv linux-amd64/helm /usr/local/bin/
[root@k8s-master01 ~]# # 检查版本号
[root@k8s-master01 ~]# helm version
version.BuildInfo{Version:"v3.16.4", GitCommit:"7877b45b63f95635153b29a42c0c2f4273ec45ca", GitTreeState:"clean", GoVersion:"go1.22.7"}
7.安装calico
查看calico组件对kubernetes集群版本的要求、(查看一下对应关系)、下载tgz格式的文件
# 下载 calico
#这里改成 Cross-Subnet IPIP 模式
wget https://docs.projectcalico.org/manifests/calico.yaml
sed -i s/Always/CrossSubnet/g calico.yaml
kubectl apply -f calico.yaml
# 验证安装状态
kubectl get pods -A # 检查 POD状态(等待 30 秒)
kubectl get pods -n calico-system # 检查 Calico 核心组件(等待 2 分钟)
kubectl get nodes -o wide # 确认所有节点状态为 Ready
测试在k8s安装pod是否可以正常访问网络
# 1. 启动临时调试容器(参数标准化)
kubectl run busybox --image=busybox:latest --restart=Never --rm -it -- /bin/sh
# 2. 容器内执行网络测试(双维度验证)
ping www.baidu.com -c 4 # 测试公网连通性[1,2](@ref)
nslookup kubernetes.default.svc.cluster.local # 测试集群内 DNS 解析[1](@ref)
# 3. 退出后自动清理容器
exit
8.测试k8s集群中部署tomcat服务
在master01节点执行
//编辑一个tomcat的yaml文件
vi tomcat.yaml
apiVersion: v1
kind: Pod
metadata:
name: demo-pod
namespace: default
labels:
app: myapp
env: dev
spec:
containers:
- name: tomcat-pod-java
image: tomcat:8.5-jre8-alpine # 关键修复:image 应与 ports 同级
imagePullPolicy: IfNotPresent
ports:
- containerPort: 8080 # 缩进对齐
---
apiVersion: v1
kind: Service
metadata:
name: tomcat
spec:
type: NodePort
ports:
- port: 8080 # 添加空格,且缩进对齐
targetPort: 8080 # 必须补充的目标端口(指向容器端口)
nodePort: 30080 # 缩进对齐
selector:
app: myapp # 修复:冒号后必须加空格
env: dev
//然后执行下面命令创建pod
kubectl apply -f tomcat.yaml
//查看pod状态
kubetcl get pods
在浏览器访问任意节点的ip+30080端口即可请求到服务。
测试coredns是否正常
kubectl run dns-test --rm -it --restart=Never --image=azukiapp/dig -- /bin/sh -c "nslookup kubernetes.default.svc.cluster.local && nslookup www.baidu.com"
10.10.0.10就是我们coreDNS的clusterIP、说明coreDNS配置好了